Getting Started
This guide will show you how to get started with using barfi. In the following example, we will use streamlit as the graphical interface to create the flow schema using a few basic custom blocks. We will then execute the flow schema for the provided blocks and check the result of the execution. As the last step we will also see how to save the created schema to be used later.
Installation
Since we will be using the streamlit widget st_flow for the graphical interface here, we will install the package with the streamlit requirements:
pip install barfi[streamlit]As a best practice, it is recommended to setup a virtual environment to manage the dependecnies of the project. If you do not know how to do this, this blog or this section could be of help.
Building your first Blocks
Let’s dive into creating your first blocks with barfi. We’ll create two simple blocks that demonstrate the core concepts: a number block that takes in a value, and a result block that processes it. This example will show you how blocks can communicate with each other through inputs and outputs, while also introducing you to options and compute functions.
The number_block allows users to input a numerical value and pass it downstream. It includes a descriptive display option and a number input field option. The result_block receives this value and simply prints it, showing how data flows between blocks.
# 01: These would be the basic imports to get started
import streamlit as st
from barfi.flow import Block, SchemaManager, ComputeEngine
from barfi.flow.streamlit import st_flow
# 02: The first block you'll create is one where you can set the number
number_block = Block(name="Number")
number_block.add_output(name="Output 1")
number_block.add_option(
name="display-option", type="display", value="This is a Block with Number option."
)
number_block.add_option(name="number-block-option", type="number")
def number_block_func(self):
number_value = self.get_option(name="number-block-option")
self.set_interface(name="Output 1", value=number_value)
number_block.add_compute(number_block_func)
# 03: The second block will be one that just prints the number
result_block = Block(name="Result")
result_block.add_input(name="Input 1")
result_block.add_option(
name="display-option", type="display", value="This is a Result Block."
)
def result_block_func(self):
number_value = self.get_interface(name="Input 1")
print(number_value)
result_block.add_compute(result_block_func)Build your first flow
Now that we have our blocks defined, let’s use the interactive flow editor to create a workflow. The streamlit widget st_flow provides a canvas where you can drag, drop, and connect blocks visually. This graphical interface makes it easy to experiment with different flow configurations without writing additional code.
The widget returns a schema object that contains all the information about your flow’s structure, including block names and connections. You can inspect this schema to understand how barfi represents your flow internally.
## ... existing code as above ...
# 04: The st_flow takes in the base blocks and returns the schema
base_blocks=[number_block, result_block]
barfi_result = st_flow(base_blocks)
# 05: You can view the schema here
st.write(barfi_result)To run the script, simply follow streamlit’s run command from the terminal:
streamlit run app.pyCreate a schema by adding the Blocks to the Flow-Editor using the right-click menu. Connect the blocks by dragging the output interface of one block to the input interface of another block.
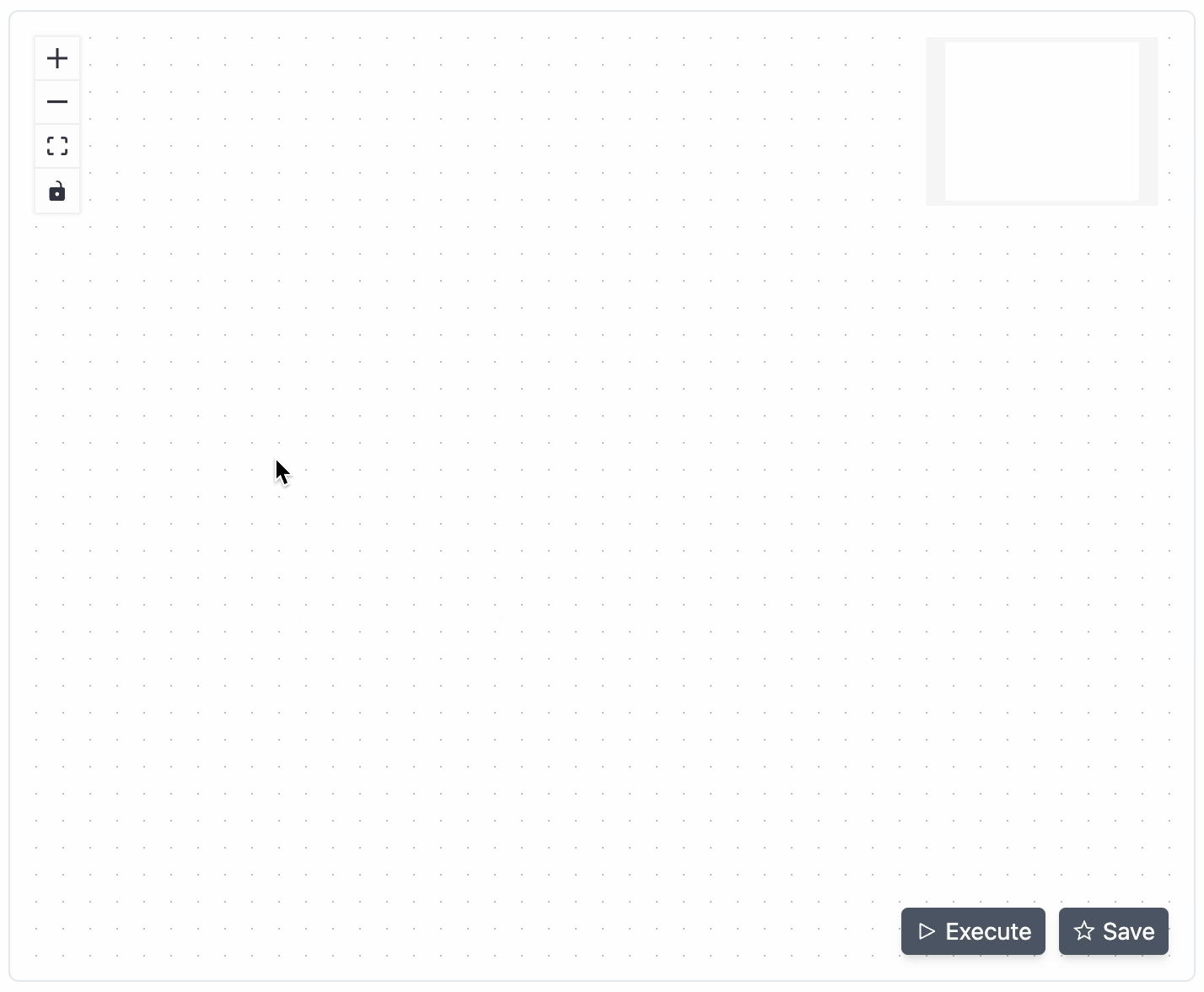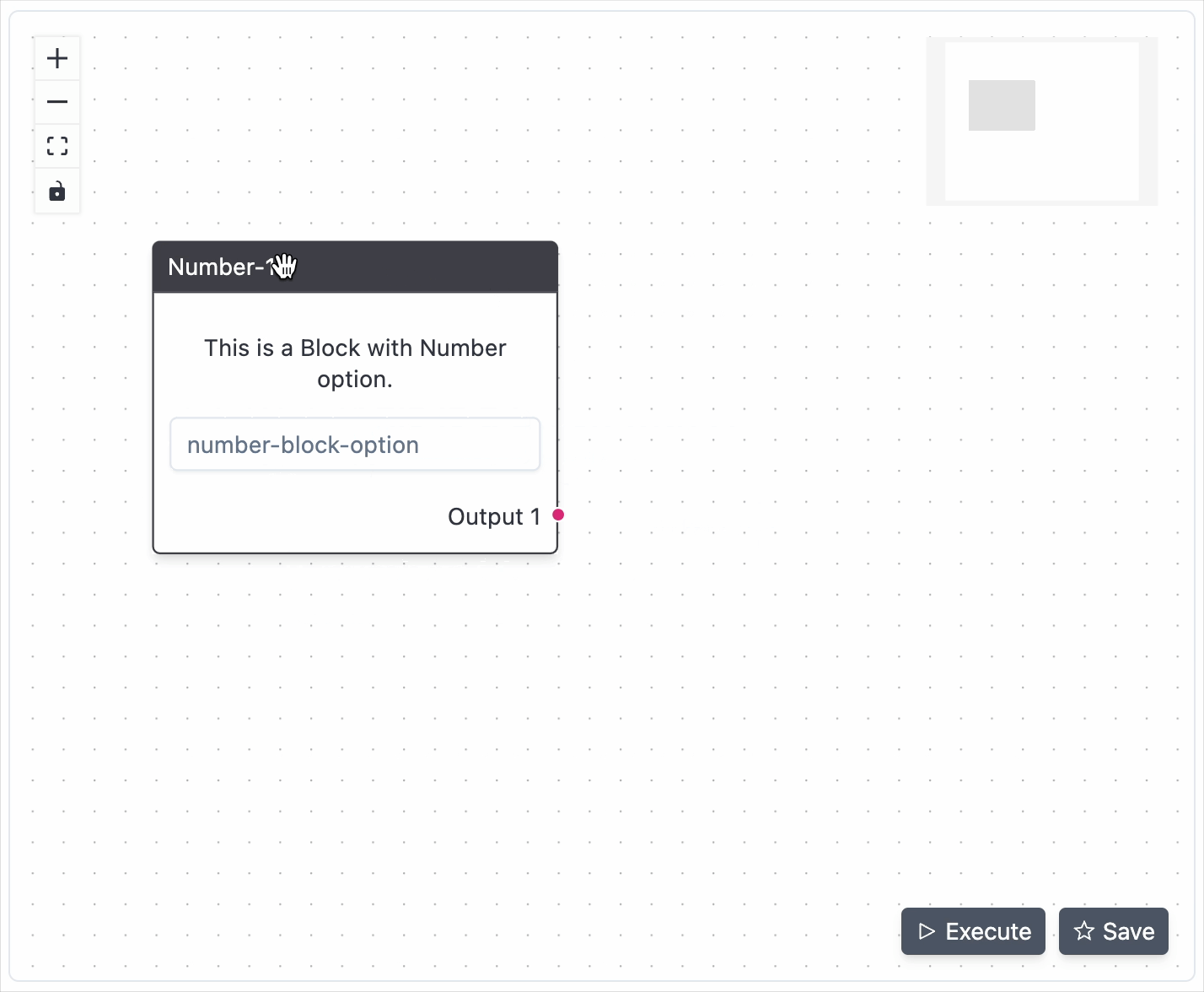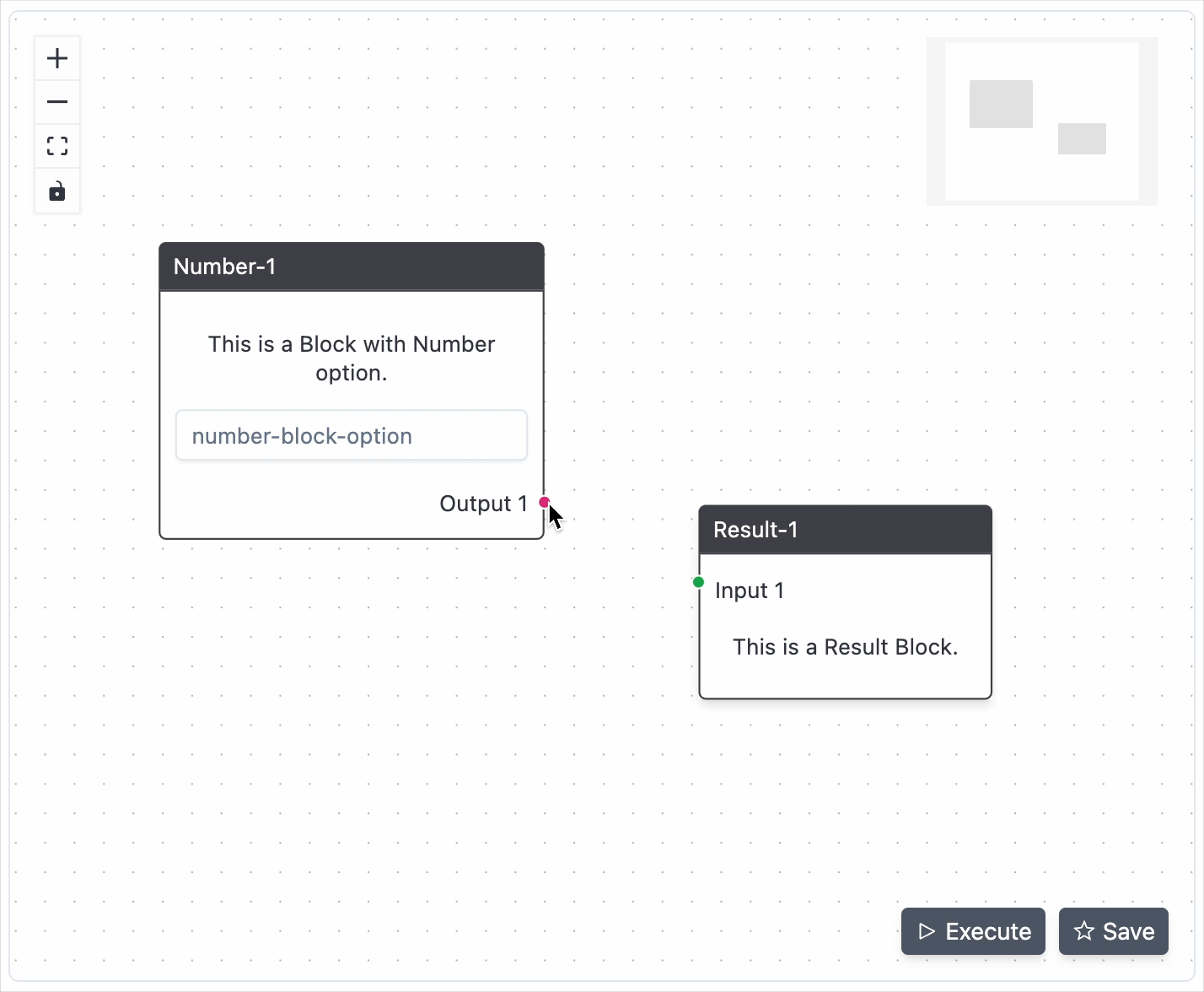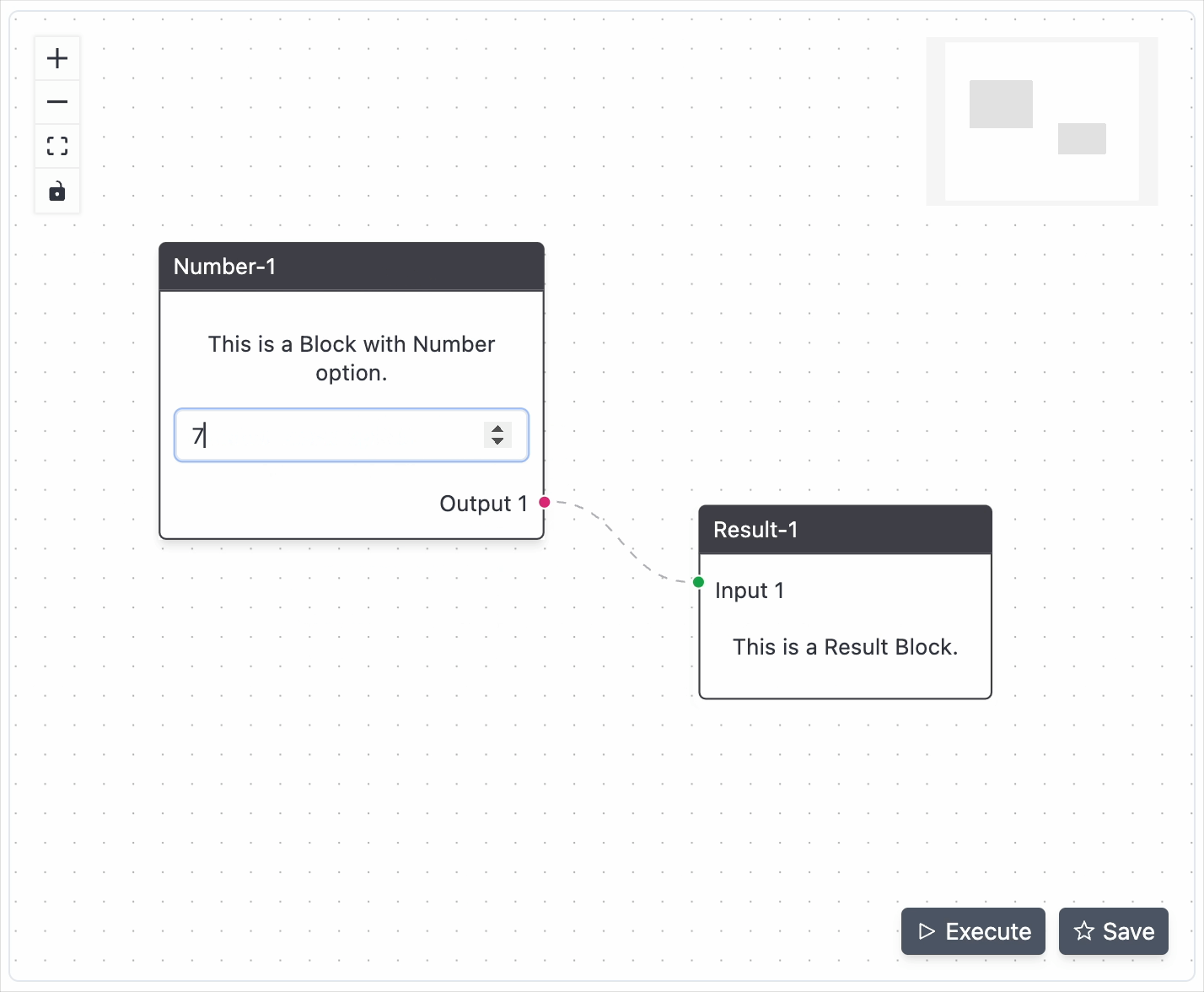
You can click and drag the Flow-Editor and also use the scroll to zoom in and out. Click on the connection or the block and use the delete key to remove them.
Upon creating a schema and clicking the execute button, the flow schema response is returned.
Run your first flow schema
With your flow schema created, it’s time to execute it. The ComputeEngine is responsible for running your flow, processing each block in the correct order based on their connections. It ensures that data flows properly from outputs to inputs across your entire schema.
The response from st_flow contains the FlowSchem at barfi_result.editor_schema. Use that to run your schema:
## ... existing code as above ...
# 06: Initialize your compute engine with the base_blocks and execute the schema.
compute_engine = ComputeEngine(base_blocks)
# 07: Reference to the flow_schema from the barfi_result
flow_schema = barfi_result.editor_schema
compute_engine.execute(flow_schema)Inspecting the Results of the Execution
Upon runnign the ComputeEngine on the FlowSchema, the execute function sets the executed Blocks in the FlowSchema. These Blocks can now be accessed to inspect the results of the execution.
For example, you can access the node with the node_label Result-1 block and its input interface value as shown below:
## ... existing code as above ...
# 08: You can inspect the result of the execution
result_block = flow_schema.block(node_label="Result-1")
result_block_input_interface_value = result_block.get_interface("Input 1")Save your flow schema
Once you’ve created a flow that works well, you’ll likely want to save it for future use. The SchemaManager provides a simple way to persist your flow schemas to disk. This allows you to build a library of reusable flows that can be loaded and modified later.
The SchemaManager is used to persist a schemas.barfi file to the disk. You can provide a path to where it can be stored and retrieved from.
## ... existing code as above ...
# 09: Initialize the SchemaManager by providing a path and save the schema
schema_manager = SchemaManager(filepath="./")
schema_manager.save_schema("my-first-schema", barfi_result.editor_schema)Conclusion
Congratulations on completing this guide! You have successfully installed barfi, created custom blocks, built your first flow schema, executed it, and learned how to save it for future use. These foundational steps equip you to explore the full potential of barfi for creating and managing complex workflows. As you continue, feel free to experiment with more advanced features and build your own reusable libraries of flow schemas. Happy workflow building!